
엔비디아 GTC 2022 Keynote
1. 요약
1.1 NVIDIA FLATFORM

1.1.1 NVIDIA SDK : 헬스케어, 에너지, 운송, 소매, 금융, 미디어, 엔터테인먼트 등 총 100조달러 규모에 사용
https://developer.nvidia.com/hpc-sdk
HPC SDK | NVIDIA
A comprehensive suite of C, C++ and Fortran compilers, libraries and tools for GPU accelerating HPC applications.
developer.nvidia.com
1.1.2 NVIDIA AI : 라이브러리, 툴 모음. 지속적인 업데이트 진행중.
NVIDIA AI는 모든 산업과 기업들이 AI를 적용하여 스스로를 재창조할 수 있도록 AI를 대중화 시킴
https://www.nvidia.com/en-us/technologies/cuda-x/
CUDA X
NVIDIA GPU-acceleration libraries for artificial intelligence
www.nvidia.com
1.1.3 NVIDIA OMNIVERSE : 가상 세계, 디지털 트윈 및 로보틱스 시스템을 위한 플랫폼
https://www.nvidia.com/ko-kr/omniverse/
가상 협업을 위한 Omniverse 플랫폼 | NVIDIA
확장 가능한 가상 세계, 디지털 트윈 구축
www.nvidia.com
1.2 NVIDIA 산업을 형성하는 5가지 원동력

1.2.1 컴퓨팅 속도 100만배 향상 → 신약 개발과 기후 과학 같은 거대한 과제에 맞설 기회 제공
1.2.2 AI를 강화하는 트랜스포머 → AI 자체 학습
1.2.3 AI 공장으로 변모하는 데이터 센터 → NVIDIA H100 3Q22 시판 예정, GRACE 23년 생산 목표
1.2.4 기하급수적으로 수요가 증가하는 로보틱스 시스템
1.2.5 다음 AI 시대를 위한 디지털 트윈
2. AI
2.1 AI 물결 → 옴니버스는 로보틱스 소프트웨어를 만드는 데 필수가 될 것
2.1.1 AI 첫번째 물결 :이미지 인식, 음성 이해, 영상 또는 구매할 제품 추천 등
2.1.2 AI 다음 물결 : 로보틱스, 즉 행동을 계획하는 AI
2.2 CUDA 라이브러리 - NVIDIA SDK* : 가속 컴퓨팅의 핵심
*SDK(Software Development Kit)
새로운 SDK가 나올 때마다 새로운 과학, 애플리케이션, 산업 분야에서는 NVIDIA 컴퓨팅의 위력을 활용할 수 있음
2.2.1 Triton : 문자 AI Open-Source Hyperscale Inference Server
2.2.2 RIVA2.0 : 음성 AI SDK for speech
2.2.3 Maxine SDK for AI Video Conferencing : 커뮤니케이션을 혁신할 최첨단 AI 알고리즘을 갖춘 SDK
2.2.3.1 대본을 읽고있는 중에도 사람들과 눈을 마주치는 형태를 보여줌
2.2.3.2 언어의 장벽도 허물 수 있음(자동 번역) 동시 두가지 언어 이상 번역 가능
2.2.4 Merlin AI Framework for Hyperscale Recommender Systems : 추천 시스템을 위한 AI 프레임워크*
*프레임워크 : 소프트웨어 어플리케이션이나 솔루션의 개발을 수월하게 하기 위해 소프트웨어의 구체적 기능들에 해당하는 부분의 설계와 구현을 재사용 가능하도록 협업화된 형태로 제공하는 소프트웨어 환경
2.2.5 Nemo Megatron : AI Framework for Training Large Language Models 매개변수가 최대 수조개에 이르는 대규모 언어 모델을 훈련하기 위한 전문 AI 프레임워크
등등 수많은 Kit가 있음.
2.2.6 새로운 AI 기술
2.2.6.1 기후 : 일기예보 AI FourCastNet
세계 최초의 AI 디지털트윈 슈퍼컴퓨터인 EARTH-2로 컴퓨팅 속도를 10억 배 높일 새로운 AI 및 컴퓨팅 기술로 늦지 않은 시일 내에 개발하겠다고 함.
2.2.6.1.1 FourCastNet : 물리학에 기반한 딥 러닝 모델로 허리케인, 대기의 강, 폭우 같은 기상 이변 예측 가능
40년에 걸친 시뮬레이션으로 보강된 유럽중기예보센터(ECMWF)의 지상 실측 정보로부터 날씨를 예측하도록 학습됨
딥러닝 모델은 처음으로 최첨단 수치 모델보다 나은 정확도와 기술을 달성했고, 예측이 10,000~100,000배나 더 빨라짐
2.2.6.2 DIGITAL BIOLOGY RVOLUTION : AI가 DNA 서열분석, 단백질 구조예측, 신약합성, 가상 약물 테스트 가속화
3. H100

- 차세대 엔진 : H100 - TSMC 4나노 공정을 사용하는 800억개의 트랜지스터 칩, TSMC CoWoS 2.5D 패키징을 이용하여 HBM3 메모리로 패키징되고 전압 조절을 통해 SXM이라는 슈퍼칩 모듈에 통합
- 스케일업과 스케일아웃을 위해 설계됐기 때문에 대역폭, 메모리, 네트워킹, NVLink 칩 투 칩 데이터 전송률이 중요함.
- 최초의 5세대 PCI-E GPU이자 최초의 HBM3 GPU
- H100 하나가 초당 40테라바이트의 IO 대역폭 지탱 → H100 20개면 전 세계 모든 인터넷 트래픽에 맞먹는 대역폭을 지탱할 수 있음
- Hopper 아키텍처는 Ampere를 넘어선 거대한 도약
3.1. H100의 성능
새로운 Tensor 처리 형식인 FP8, 4페타플롭의 FP8, 2페타플롭의 FP16, 1페타플롭의 TF32, 60테라플롭의 FP64 및 FP32
공랭 및 수랭식으로 설계된 H100은 또한 700W까지 성능을 스케일인 하는 최초의 GPU
Hopper H100의 4페타플롭에 이르는 FP8은 Ampere A100의 FP16의 6배에 달하는 성능
| NVIDIA H100 | ||
| FP8 | 4,000 TFLOPS | 6X |
| FP16 | 2,000 TFLOPS | 3X |
| TF32 | 1,000 TFLOPS | 3X |
| FP64/FP32 | 60 TFLOPS | 3X |
3.2 Hopper Transformer engine : Dynamic Mixed-Precision Processing
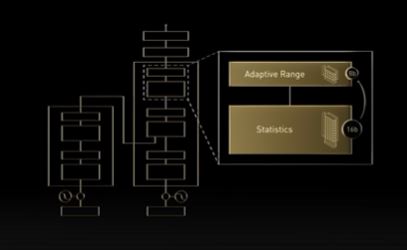
FP8 및 FP16 수치 형식을 사용하는 소프트웨어와 새로운 Tensor Core를 결합하고, 트랜스포머 네트워크의 계층을 동적으로 처리
3.3 Hopper Confidential Computing : Secure Deployment of Ai Models
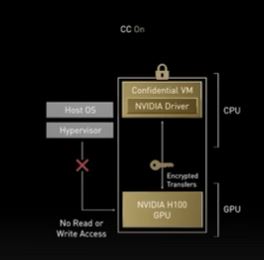
새로운 명령세트인 DPX : 동적 프로그래밍 알고리즘을 가속화
New DPX Instructions : 40X Speedup for Dynamic programing
동적프로그래밍은 복잡한 문제를 재귀적으로 해결되기보다 간단한 하위 문제로 분해하여 복잡도와 시간을 다항식 규모로 줄임. Hopper DPX 명령은 이러한 알고리즘의 속도를 최대 40배 높임
3.4 HGX H100

8개의 H100 SXM 모듈은 HGX 시스템 보드의 NVLink 칩 4개로 연결
| HGX H100 | ||
| FP8 | 32,000 TFLOPS | 6X |
| FP16 | 1,6000 TFLOPS | 3X |
| FP64 | 480 TFLOPS | 3X |
| In-Network Computer | 3.6 TFLOPS | ∞ |
| Bisection Bandwidth | 3.6 TB/s | 1.5X |
3.5 CONNECTX-7

8 Billion Transistors TSMC 7
400G GPUDirect Throughput
400G Crypto Acceleration
405 Million/sec Message Rate
3.6 DGX H100

NVLink로 연결된 DGX는 8개의 H100을 하나의 거대한 GPU로 만든다.
DGX H100: Fortune 10대 기업 중 8개, 100대 기업중 44개 기업의 AI 인프라로 사용 중
8 H100 GPUs (640 Billion Transistors)
32 PFLOPS of AI Performance
640 GB of HBM3 Memory
24 TB/s of Memory Bandwidth
3.7 DGX POD WITH NVLINK SITCH

NVLink를 통해 최대 32개의 DGX 연결
20.5 TB of Total HBM3 Memory
768 TB/s of Memory Bandwidth
AI 공장의 경우 DGX는 가장 작은 컴퓨팅 단위
NVLINK 스위치 시스템을 통해 거대한 하나의 32노드, 256GPU DGX POD로 확장 가능
각 DGX는 쿼드 포트 광학 트랜시버를 통해 NVLINK 스위치에 연결됨
각 포트에는 초당 100GB의 100G-PAM4신호 전송을 위한 8개의 채널이 있음
3.8 DGX POD WITH NVIDIA H100

1 EFLOPS of AI Performance 6X
20 TB of HBM3 Memory
192 TFLOPS of SHARP In-Network Compute 15X
70 TB/s of Bisection Bandwidth* 11X
*Bisection : GPU간에 데이터를 이동하는 대역폭
3.9 Eos : 세계에서 가장 빠른 AI컴퓨터가 될 것으로 기대
A100으로 구동되는 미국에서 가장 빠른 과학 컴퓨터인 summit보다 1.4배 빠른 275페타플롭 기록
AI에서 세계에서 가장 큰 슈퍼컴퓨터인 일본의 Fugaku의 4배에 달하는 처리능력인 18.4 엑사플롭 기록
OEM 및 클라우드 파트너를 위한 가장 발전한 AI 인프라의 청사진
18 DGX POOS
FP8 18EFLOPS 6X
FP16 9EFLOPS 3X
FP64 275PFLOPS 3X
In-Network Compute 3.7PFLOPS 36X
Bisection Bandwidth 230TB/s 2X
H100 DGX SuperPOD 전체를 구입하거나 NVIDIA 플랫폼 4개 계층의 기술 구성요소 구입 가능
현재 건립 중이며 몇개월 안에 가능
3.10 Grace CPU
https://www.nvidia.com/ko-kr/data-center/grace-cpu/
Grace 소개
테라바이트 규모의 데이터를 실행하는 서버를 위해 특별히 제작된 CPU
www.nvidia.com
Superchips Connected by NVLink C2C
144 cPU Cores
1 TB/s LPDDR5X with ECC
396MB on-Chip Cache
'기업분석' 카테고리의 다른 글
| 엔비디아 GPU 수요 감소 (2) | 2022.04.25 |
|---|---|
| 10-K와 GTC로 보는 엔비디아 경제적 해자 분석 (2) | 2022.04.10 |
| 펄어비스 리포트(이베스트 22.3.14) (0) | 2022.03.16 |
| 셀트리온그룹 회계 감리 결과 이슈(하나금융 22.3.14) (0) | 2022.03.14 |
| 네이버 & 카카오 기업 리포트(교보증권 22.3.7) (0) | 2022.03.11 |



